Why this matters now
The hardest thing about working with experts is that you cannot see what they do. A senior auditor's judgment on an unusual transaction. The physicist deciding which anomaly is worth chasing, the fraud analyst reading a pattern as off, the clinician sensing that the presentation does not quite match the diagnosis. The reasoning happens inside the expert's head, and what leaves the head is a conclusion. The considerations, the rejections, the hesitations, the workarounds, the moments where the expert almost decided differently: none of that is visible to anyone else, including to the organization that depends on the work being done well.
This was not always the shape of the problem. The guild system, for all its closures and hierarchies, had one feature modern professions have never replicated at scale: the master's work was visible to the apprentice, daily, over years. Expert judgment passed through shared practice. When the guild model gave way to the modern profession, with its credentialing, licensing, and formal education, we traded something we had for something we needed. We gained the ability to produce experts at the scale an industrial society required. We lost the continuous observation that had made expertise transmissible. The gap has lived there ever since, and it is part of the reason serious expert professions still require so much education before practicum. Assessing whether someone can do expert work cannot be done by examining their outputs alone. You have to watch the work, across varied conditions, for a long time. We do this in clinical residencies, in audit engagements, in graduate research. We do it badly and slowly and expensively, because we have not had another way.
Agentic AI is the first technology that changes this. When an expert's work gets delegated to an AI system, every step the system takes leaves a trace. The retrievals it performed. The tools it called. Which alternatives it considered, how it arrived at its intermediate conclusions, the path it chose through the problem. All of it is inspectable. For the first time, a large class of consequential knowledge work is producing a telemetry layer. This is not just new instrumentation. It is a partial restoration of something the modern profession gave up, now available at a scale the guild could never have reached. What that opens is not that AI is doing the work. It is that AI is doing the work in a way that can be observed, and what gets observed can be measured, and what gets measured can be improved.
This is the argument most current discussion of agentic AI is missing. The debate is fixated on what these systems can do, and whether they should be allowed to do it, and who is responsible when they do it badly. All three are live questions, and all three are bound to this moment. The more durable question is what the telemetry of these systems makes possible that nothing before them made possible, which is a real operational discipline for work we have never been able to instrument.
A telemetry layer is not the same as that discipline. Raw traces are not measurements. Measurements are not fitness. Turning telemetry into a running answer to the question "is this system doing the work well, on this case, right now" requires a stack of layers that take raw signal and turn it into something an expert can act on. It also requires experts to define what "well" means. No amount of AI-monitoring-AI replaces the standard-setting that has to be done by the person whose work is on the line.
This is the first of three pieces on what it takes to build that discipline. The frame I am using is fitness, not as the regulatory checklist item it has become in most current discussions, but as a continuous operational property of a system in use, measured and maintained against the standards the expert defines. The closest functional analog I know for the stack that produces that property is weather forecasting, which has spent a century building exactly this kind of stack for exactly this kind of expert decision. The next two pieces will treat the diagnostic framework underneath the stack and the reason the stack survives architectural change. This one introduces the shape.
Why weather
Last year, writing about how AI systems should be evaluated, I argued that weather was the right metaphor for their behavior. These are complex, adaptive, emergent systems, and the evaluation approach that works for clockwork fails for them. That argument was about how agentic AI behaves. This piece is about a different property of weather: how we operate around it.
Weather forecasting exists because the atmosphere is complex, adaptive, and consequential to expert decisions. A pilot deciding whether to fly, a farmer deciding whether to harvest, an emergency manager deciding whether to evacuate, a ship's captain deciding whether to sail: each of these is an expert making a consequential call on incomplete information about a system they cannot fully observe and do not control. The forecasting stack exists to serve those decisions. It has been refined over a century, through every scale from the local weather station to the global model, to do one specific job: turn the raw atmospheric signal into artifacts the expert can act on.
Agentic AI in expert-driven work faces the same shape of problem. The underlying system is complex and adaptive, the work depends on properties the expert cannot directly observe, and the stakes are high enough that being wrong has real consequences. If the forecasting stack worked for atmospheric complexity, it is worth examining whether an analogous stack does the same job for agentic AI. The claim is not that weather and AI are the same. It is that the shape of the problem is the same: a complex system, an expert decision, a consequential outcome, and a gap between them that an engineered stack is meant to close.
Here is what the stack looks like.
The functional stack
The fitness stack for agentic AI has the same shape as the forecasting stack. It has five functional layers, each doing a distinct job in the chain from raw signal to expert decision, and each layer consumes what the layer below produces and hands something more interpreted to the layer above. None of the layers is sufficient on its own, and an AI operations team looking only at one or two of them is working with a partial forecast.
The difference between a monitoring stack and a fitness stack is not how many layers it has. It is what question each layer answers. Current AI monitoring tells you whether the system is running, whether the trace completed, whether the tokens stayed in budget, whether the retries succeeded. Those numbers are real, and they are useful to the teams operating the platform, but they do not tell you whether the flight is on course. A plane can be running perfectly while heading in the wrong direction, and an agent can be executing cleanly while producing work the expert would not accept. Whether the output is grounded in its sources. Whether the agent followed the specified procedure. Whether two related outputs are consistent. Whether engagement content has bled across clients. These are the measurements that tell you whether the work is reaching its destination. They can only be designed by someone who knows where the destination is, which means they can only be designed with the expert in the room. A fitness stack is the same shape as the observability stack, but every layer is instrumented to answer a question the expert would recognize as their own: is the work getting where it needs to go.
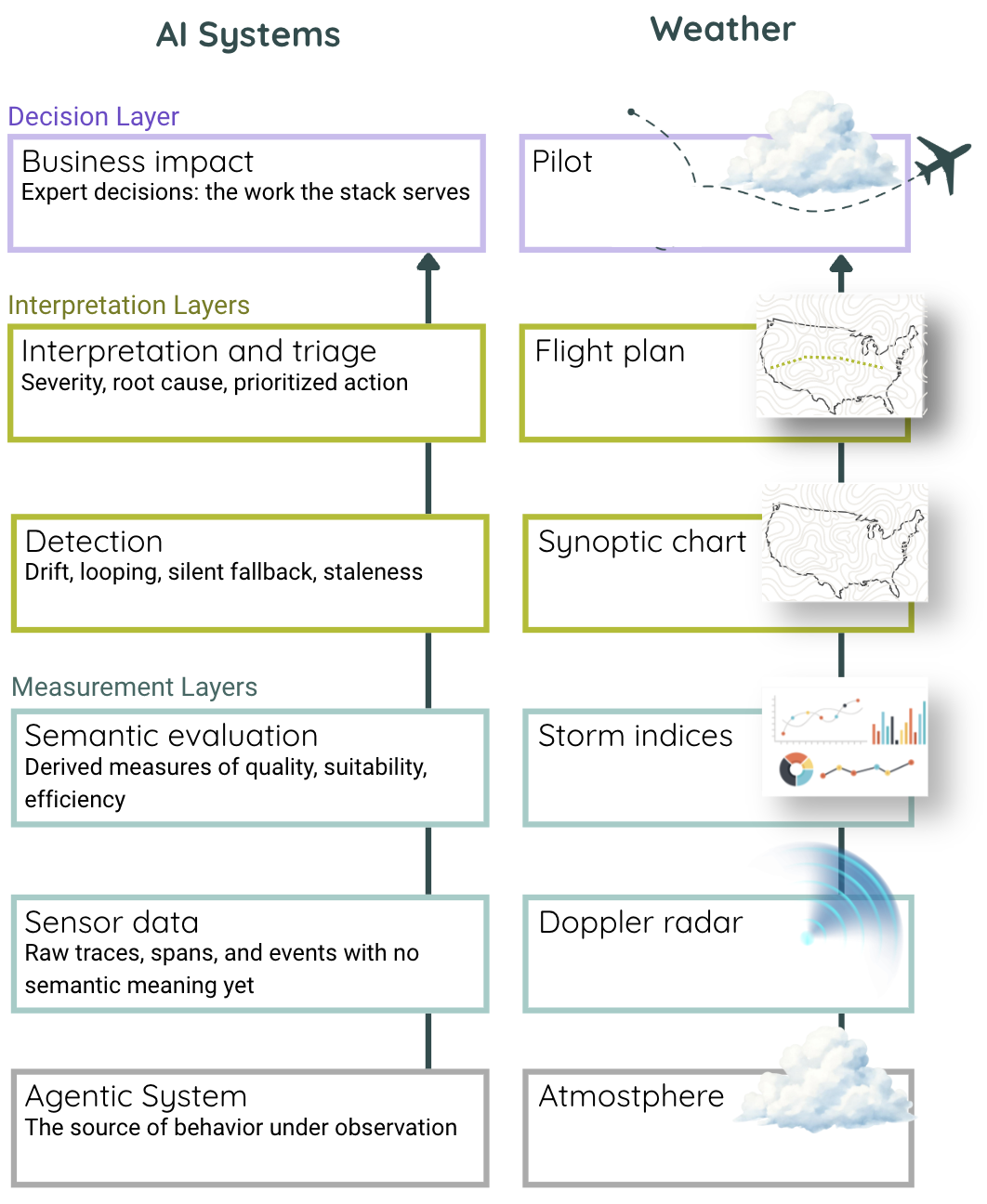
Sensor data. The bottom of the stack is the raw feed: traces, spans, tool calls, retrieval events, token counts, timing data, structured logs from whatever the agent did. In a well-instrumented agentic system, this layer is dense, because every step the system took leaves a trace, and every trace carries enough metadata to reconstruct what happened. But a trace is not an answer, and a complete log of every step an agent took does not tell you whether the work reached its destination. It tells you what the system did, not what the work required. This is Doppler radar. Radar returns show where the water vapor is and how it's moving, but that is not the same as knowing whether a storm is forming, and a pilot reading raw radar cannot yet plan a flight. The sensor layer is necessary, precise, and insufficient on its own.
Semantic evaluation. The next layer up derives meaning from the raw feed. Where sensor data tells you what the system did, semantic evaluation scores it on quality, suitability, and efficiency. Was the output grounded in its sources? Did the agent follow the instructions the procedure specified? Did the work complete without consuming disproportionate cost or human review? These are computed measurements. They do not appear in the raw trace; they have to be calculated from it, against evaluators that know what the work is supposed to look like. This is where the expert's knowledge first enters the stack, not in reading dashboards, but in defining the standards the evaluators apply. Storm indices work the same way. CAPE and shear don't appear on the radar. A meteorologist computes them because they know what to look for, and a pilot trusts them because the indices were designed around the questions flights actually face. Semantic evaluation is necessary, interpretable, and still not enough.
Detection. Semantic evaluation scores each output in the moment. Detection asks a different question: how is the system behaving over time, and has something changed? A single output can be grounded and well-formed and still sit inside a pattern that is quietly going wrong, whether that pattern is outputs drifting away from their calibration, the same step looping without converging, a retrieval system silently falling back to a weaker method when the right one fails, or stale outputs persisting after the conditions that produced them have changed. None of these show up as a single bad score. They show up as patterns across many scores, across many runs, sometimes across days or weeks. The synoptic chart does the same work. Individual pressure readings and wind vectors don't tell a pilot much, but the chart assembles them into a picture of what the weather system is doing and where it's heading, which is the picture a flight plan is built against. Detection is necessary, behavioral, and only meaningful once someone knows what to do with it.
Interpretation and triage. Detection produces findings. Interpretation turns findings into an artifact the expert can act on, covering what happened, how severe it is, what it's likely caused by, what to do about it, and in what order. Ten findings become three priorities, and a pattern of silent fallbacks becomes a categorized issue with a named owner and an action window. This is where the stack stops describing the system and starts producing something for a specific audience, the expert whose work depends on the system being reliable. The flight plan does the same work. Raw synoptic data is a description of the weather, but a flight plan is a document built for this pilot, this flight, this route, with the weather translated into operational choices: altitudes to hold, regions to avoid, alternates to file. The measurements are the same; the artifact is different because the audience is. Interpretation is necessary, expert-facing, and the first layer in the stack that belongs to a named person.
Business impact. This is the top of the stack and the point of it. Everything below, from the raw traces to the computed scores to the behavioral patterns to the triaged findings, exists to serve a decision only the expert can make: whether to accept the output, hold the engagement, escalate, rerun the procedure, revise the workpaper, or stop the deployment. These are not platform decisions. They are the expert's judgments, bearing the weight of the work itself, made on a specific case with specific stakes. The pilot makes the same kind of call, deciding whether to fly, divert, change altitude, or abort. The stack behind them, radar, indices, synoptic picture, flight plan, has done its work if the pilot is now making that call with more of what they need and less of what they don't. The stack cannot make the call for them. It can only ensure that when they make it, they are on course for where the flight is trying to go. This layer does not belong to the platform. It belongs, finally, to the person whose work is on the line.
What the stack is for
A framework that does not serve a decision is a diagram. What the fitness stack produces, when it is built well, is a running answer to a question only the expert can ask and only the expert can act on. Is this system doing the work I need it to do, right now, on this case, well enough for me to stand behind what comes next. That is the question every serious expert asks about every instrument they rely on, agentic or otherwise. It has never been possible to ask it of expert work itself at scale. It is now.
None of this happens by accident, and none of it happens without the expert in the design. A stack assembled without them will produce impressive dashboards and fail the only test that matters. A stack built with them will produce measurements the expert recognizes as their own, delivered as artifacts calibrated to their work, arriving at the moment they need to act. The difference is not technical. It is structural. The expert is not a consumer of the stack. They are its upstream author, and their judgment is the standard the whole thing is instrumented against.
This carries an ethical dimension worth naming. Making expert work legible is powerful, and power accrues to whoever holds the measurement. If the stack is designed by experts, it serves their judgment and their work. If it is designed over their heads, it can be used to discipline them, replace them, or strip them of the authority that comes with being the person who decides. The history of standardization is full of both outcomes. The fitness stack this series describes is one that has to be built with experts, not around them.
The next piece in this series treats the diagnostic framework that sits underneath the stack: five tiers of observation, each unlocking a category of detection that the layers above depend on. The piece after that treats the reason the stack survives architectural change as systems decompose into skills, tools, and compositions we have not yet named. Together, these three pieces lay out what it takes to build a practice that is fit for expert work.