A few decades ago, pulling a figure off an invoice meant finding the physical document in a cabinet and reading the line. Then it meant locating the field on a scanned PDF, or relying on technology that could point to it. Now it means judging whether an agent pulled the right figure from the right document for the right reason. At each step the skill changes, but the judgment underneath the skill does not vanish with the task itself. It moves into verification.
That movement runs all the way up the organization, because at every level the work is now done through agents. The practitioner verifies an output instead of generating it. The reviewer verifies a pattern across outputs they did not produce. The director verifies consistency across workstreams no single person touches. The activity is the same at each altitude, only the scope widens: you are checking work you did not fully do yourself.
That is harder than it sounds, and it depends on something fragile. Verification at scale is only possible if the judgment behind the work survives the handoff, and what has to survive is exactly the part that used to travel invisibly: the reasoning behind a conclusion, the place where someone was uncertain, the alternative that was weighed and set aside, the correction that was applied and whether it has been needed before. In the old organization that signal moved through review meetings, side conversations, and the half-sentence someone added to explain why the answer was not quite as straightforward as it looked. It was lossy and inefficient, and it carried the work. A clean agentic handoff can strip it away, delivering an output that is complete, confident, and silent about the judgment that produced it, so that the very information you need in order to verify the work disappears at the moment the work looks most finished.
If you operate inside one of these systems, you have probably felt this already, wherever you sit in it. The dashboards tell you the system is running: latency is fine, calls are succeeding, nothing is on fire. What they do not tell you is whether the work is any good. You are competent, you have the best tools available, and still you are quietly drowning — because nothing shows you where your judgment is load-bearing and where the system is running fine without you. So you check everything, or you check nothing and hope. The rest of this piece is about what becomes visible when you stop watching the system and start watching the work.
When failures move up a level
Anyone who has built an agentic system knows what a loop looks like. The agent calls a tool, evaluates the result, decides it is not yet done, and calls again, and under the wrong conditions that cycle never converges: the same retrieval reissued, the same plan reconsidered, the same step attempted with no progress toward closing it out. It is one of the first failures an engineer learns to watch for, and at the level of a single agent it is usually loud and cheap to detect.
The interesting thing is that looping does not stay there. Lift the scope from one agent to an orchestration of several, and the same failure reappears as agents handing work back and forth without the run advancing. Lift it again, to a composition of services, tools, and people, and it reappears as work that circulates without resolving. A figure goes out for review, comes back with a question, is revised, goes out again, and returns with the same question, because the thing that would close the loop was never passed along: the missing context, the unrecorded reason, the judgment nobody captured. The loop now runs through a person, but it is still a loop.

That is the useful fact: some failures in agentic systems are scale-structured. They recur in recognizable shapes across the scopes of the work because the underlying conditions recur there too: composition under uncertainty, partial observability, dependence on an upstream result that failed silently. This does not mean every layer needs its own vocabulary of failure. It means the same small set of failures can be observed at the level where each one becomes visible and consequential. The question is what those levels are.
This is worth sitting with, because a great deal of current effort goes into cataloguing agentic failures by where they occur in the system. That work is interesting if your subject is the system. But the failures are not really a property of the system; they are a property of the work the system is doing, which is why the same ones recur no matter how the system is built. A taxonomy organized around the architecture is answering a question about the architecture. Most enterprises have a different question, about the work, and the failures will be there waiting at whatever level you choose to watch. So the useful move is not to catalogue failures by system. It is to watch the work, at the levels where the work can go wrong.
The scopes belong to the work
There are five scopes of observation. They are not an org chart, and they are not a system architecture; they are the levels of the work itself. That is the whole point of choosing them: an architecture is a temporary arrangement, but the work has to be done regardless of which arrangement is doing it, so scopes drawn around the work survive when the org chart is redrawn or the system is refactored underneath them. Each scope sees something the scope inside it cannot.
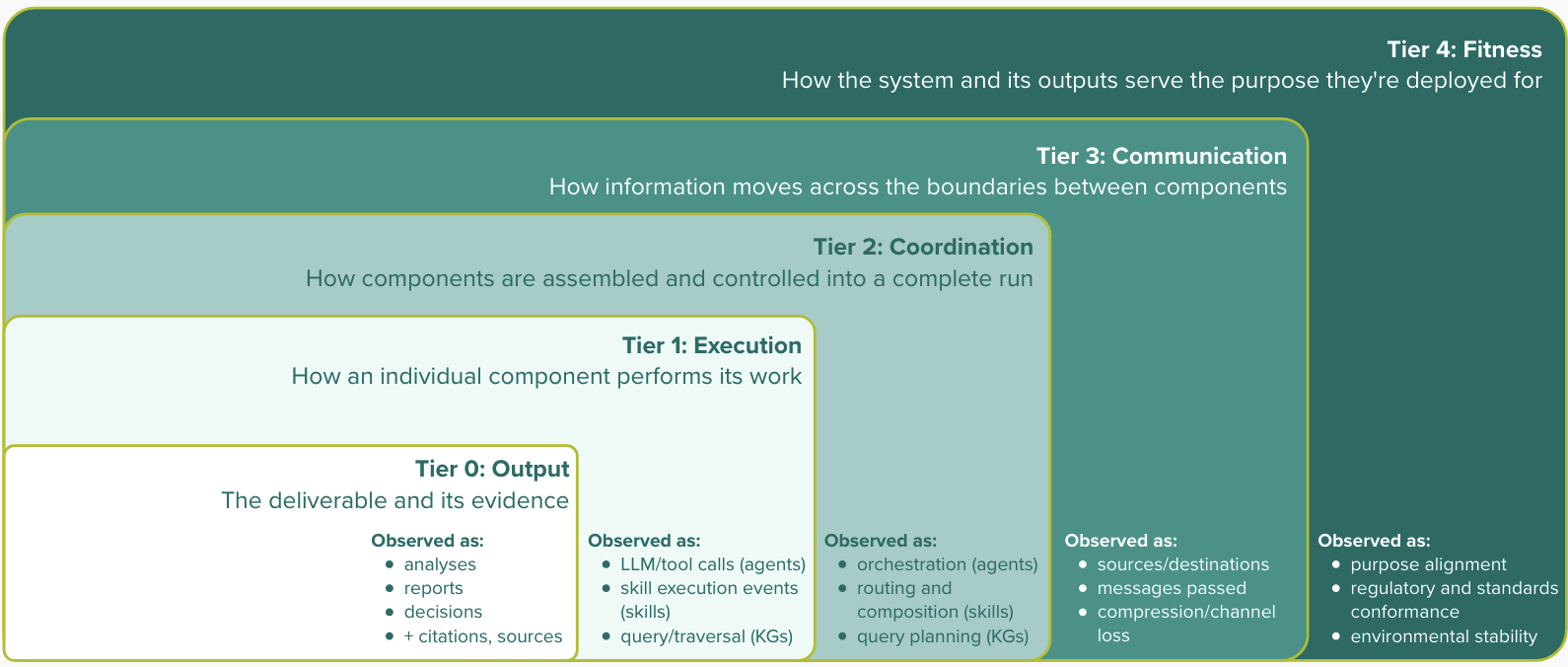
Tier 0, Output.
The deliverable and its evidence. This is where the trust question lives: Is this conclusion right, and can I see what it rests on? It is also where most accuracy attention stops, even though an output can be correct in form and still be the product of a process that failed somewhere the output does not show.
Tier 1, Execution.
How an individual component performs a single step, right or wrong in isolation: an extraction, a retrieval, a tool call, a classification, a traversal. This is where most engineering instrumentation already operates. It can tell you whether the step did what it was supposed to do. It cannot tell you whether the step should have been taken at all.
Tier 2, Coordination.
How components are assembled into a complete run. A run can be built entirely from correct steps and still be wrong as a whole: a dependency silently skipped, a gate bypassed, an order of operations that no individual component is responsible for and none of them can see.
Tier 3, Communication.
What moves through the channels once the components are connected. In practice, Tier 3 is the difference between receiving a completed workpaper and receiving the workpaper plus the uncertainty, correction, override, and escalation history that tells a reviewer what kind of judgment produced it.
Tier 4, Fitness.
Whether the system’s outputs remain fit for the purpose they are meant to serve. This is the only scope that compares the system against something outside itself: the standards the work is accountable to, the environment it operates in, and the purpose it was commissioned for. This is where the business consequences live, and also where the most common measurement error lives. A benchmark scores an output against a known answer, which is a Tier 0 measurement, and the persistent mistake is to read fitness off it. A real fitness benchmark would have to exercise all five scopes, but a test that exercises all five scopes is no longer a benchmark; it is the work itself. Fitness is not something you measure once on the side. It is observed in the running system, which is why the tiers describe what to watch rather than what to score.
The tiers are useful because they keep observation attached to the work rather than to the temporary shape of the system. The architecture can change, but the work still has outputs, steps, coordination, handoffs, and a purpose it has to remain fit for. That is what makes the scopes stable enough to monitor against.
The handoff is the load-bearing tier
The reason Tier 3 carries the most weight is that it is where the claim from the previous post becomes operational: the intelligence an organization holds lives partly in its edges, in what gets passed, corrected, and escalated between people, not only in the people themselves. In an agentic system those edges are no longer only human. The component handing off can be a model, a tool, a service, or a person; so can the one receiving. What matters is the channel between them: what was passed, what reasoning survived the handoff, what uncertainty was compressed away, and whether the receiver can reconstruct enough of the judgment to verify the work.
This is also where the machine becomes useful as an instrument, not because the machine is the work, but because it can emit evidence of the work as it happens: the source used, the alternative rejected, the user correction, the override, the escalation, the repeated workaround. These traces are not just system telemetry. In expert work they are evidence about how judgment is moving. When an expert receives an output and corrects it, overrides it, escalates it, or works around it, those actions are not noise around the real work; they are the verification happening. A correction says the output was recoverable and shows what it should have been. An escalation says the failure exceeded what one person could absorb. A workaround says the system could not support the work, so the expert went around it. Read across many handoffs, these responses show where judgment is being exercised, where it is being lost, and where the system is quietly failing in ways no single output reveals.
That is why signal loss is the central failure at this tier. A reviewer can re-examine a single output, but a director cannot re-examine every output beneath them: their judgment is only as good as the signal that survived the climb. When nothing flows upward but polished outputs, the top of the organization is verifying a process it can no longer see.
This does not require every act of verification to stay human. Some checking will itself be done by agents, monitors, or other automated systems. But automating the checker does not remove the problem; it moves the problem up a scope. The system still has to expose what was checked, what the check relied on, what uncertainty remains, and where accountability for the work finally lands.
The goal, then, is not to monitor the machine instead of the work. It is to instrument the machine so the work remains legible. The same signal that makes a failure detectable to the system is the signal that makes the work verifiable to the human responsible for it. Detection and legibility are not separate features. They are the same property, viewed from two sides.
What the edges can carry now
None of this is new knowledge to the organizations that will use it. The idea that you improve work by watching the process, not just the finished output, is what the quality movement spent decades establishing, and expert firms have always known where judgment lives and what their controls are meant to catch. What they have not had is a way to watch it continuously: capturing the signal meant pulling people off the work to sample it by hand, slowly and at a cost that made it rare. The constraint was never knowing what to watch. It was affording to watch as the work happened.
That is what has actually changed, and it is the part that is new. When the work is done through agents, and the channels between them are built to carry the right information, the signal becomes a byproduct of the work rather than an apparatus bolted on afterward. The same information technology that does the work can carry the evidence of how it was done, and increasingly help read it, verify it, and improve on it. The thing the quality movement knew to look for has finally become cheap to see, and the handoff, the most critical place to watch, is the place this is most true.
That does not make the work easier for people. In many ways it makes the human work more demanding, because verifying across these scopes is harder than producing at one of them: the expert now has to evaluate work they did not personally produce and understand failures that may have formed several steps away. Each task still carries a skill of its own, and those skills keep changing, the way locating a receipt in a cabinet gave way to finding a field on a scanned PDF and will give way again to checking what an agent returned. The skills turn over with the tasks. The judgment underneath them does not, and it becomes more important, not less.
But this is not a transition that happens on its own. When manufacturing moved offshore, the work that stayed behind shifted from making things to monitoring the processes that made them, and monitoring turned out to be a genuinely different aptitude, closer to the discipline an operations team brings to a running system than to the craft of the line*. The same shift is now arriving in expert work, and it is why helping people climb cannot be left to chance: the producer does not become a verifier for free. The same signal that makes the work legible to a reviewer is also what teaches the next person how to verify, because it shows what was noticed, what was missed, what was corrected, what was escalated, and why. In a distributed, AI-assisted organization, that may be the closest thing to apprenticeship the system can offer.
The organizations that pull ahead will not be the ones that capture the most signal. They will be the ones that make the signal useful: legible to the practitioner trying to learn, the reviewer trying to verify, the director trying to see a pattern, and the leader trying to understand whether the system is improving or degrading. Holding that signal close and rationing it by level only rebuilds the bottleneck the instrumentation was meant to relieve.
The five scopes are a way to organize that signal. They describe what has to be observed and what has to be passed along for the work to remain verifiable, whether the system underneath is one agent, an orchestration of fifty, or a set of composable services that will be refactored again next quarter. The architectures will keep changing, which is why the monitoring cannot be organized around the shape of the current system. It has to be organized around the work the system is doing, and the human judgment still accountable for it.
The machine may be what emits the trace, but the work is what gives the trace meaning.
So, we should instrument the machine, and then measure the work.
* Many thanks to Melissa Reeve for this example during her RMAIIG panel.